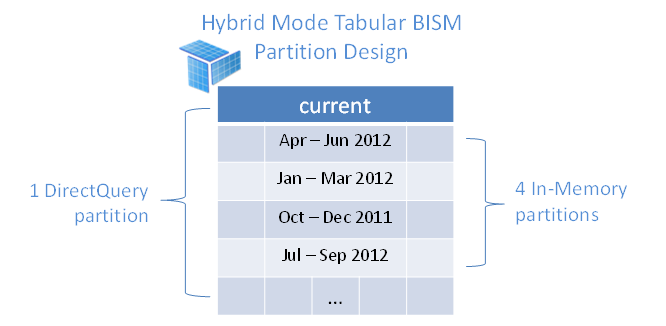
This is Part 2 of the Hybrid Mode in Tabular BI Semantic Model series, where we will learn more about the design tips, a few factors to consider on Hybrid mode implementation and a summarised advantages and limitations of Hybrid Mode.
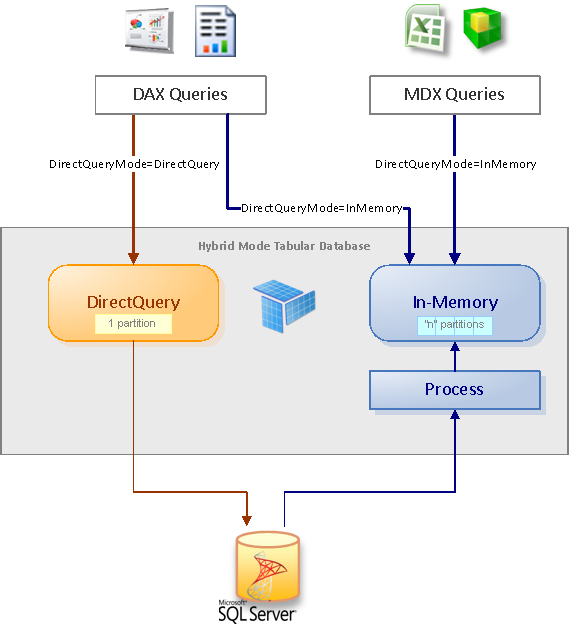
Basic walk-through of Hybrid Mode in SSAS Tabular. Tabular databases with Hybrid mode are designed in DirectQuery, but published with either of the two available hybrid Query Modes.
Performing "Process Full" on the Tabular Model database would incorrectly show "Process Recalc" instead via SQL Server Management Studio.

Julie Koesmarno presenting DirectQuery vs Vertipaq Mode in SSAS Tabular Model at SQL Saturday #138 in Sydney and SQL Rally Dallas 2012.
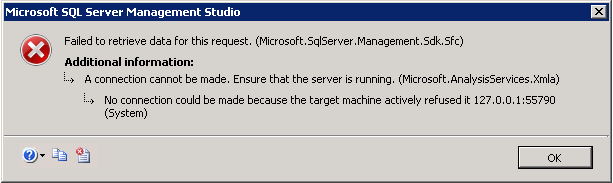
How to undo misconfigured and non-startable Analysis Server Propeties by editing the msmdsrv.ini file

So you've heard SQL Server 2012 release is coming very soon, with its Virtual Launch Event on 7 March 2012. Have you tried SQL Server 2012 RC0 yet?